VM devirtualization using AsmJit
Later in August me and my teammates from SFT0 were organizing YauzaCTF 2021 compitition. Amongst all the challenges there was 1 with a virtual machine which i’d like to address today.
VM Architecture
This vm is a stack based virtual machine with 1 to 1 mapping between physical and virtual registers. Instead of using one single dispatcher, every handler has its own dispatcher attached to it. Also, there are 512 “unique” handlers of every virtual instruction meaning the obfuscation and physical registers in handlers may differ.
The vm uses rolling decryption key. This key is used to decrypt next handler or virtual instruction operand. The rolling key is updated after every bytecode access.
Below is a sequence of instructions used to decrypt bytecode value and update rolling key:
; r8 - holds bytecode ptr
; r10 - holds rolling key
mov rax, [r8] ; read encrypted value from bytecode
add r8, 8 ; advance bytecode ptr
xor rax, r10 ; decrypt value
ror rax, 5 ; decrypt value
xor r10, rax ; update rolling key
This type of encryption prevents you from starting disassembling at any given point in instruction stream. The only way to decrypt next handler address is to follow vm execution.
VM Entry
Before execution starts, vm saves all general purpose registers onto the stack, sets virtual instruction pointer, virtual register pointer and rolling key register:
; Save context
push rax
push rbx
push rcx
push rdx
push rdi
push rsi
push rbp
push r8
push r9
push r10
push r11
push r12
push r13
push r14
push r15
; Setup virtual machine
lea r8, bytecode ; r8 - Holds bytecode ptr
mov r9, cs:virtual_registers ; r9 - Holds virtual registers ptr
mov r10, 1337DEAD6969CAFEh ; R10 - Holds Rolling key
; Start execution
mov rax, [r8]
add r8, 8
xor rax, r10
ror rax, 5
xor r10, rax
jmp rax
VM Exit
Unlike VM Entry, here general purpose registers are poped from the stack:
pop r15
pop r14
pop r13
pop r12
pop r11
pop r10
pop r9
pop r8
pop rbp
pop rsi
pop rdi
pop rdx
pop rcx
pop rbx
pop rax
retn
Handler obfuscation
Besides different ror shifts, every VM handler has unique “garbage” instructions added before handler logic and after handler logic to harden dumb signature scanning. Consider the following:
VM_READ_8 proc near
neg esi ; garbage block 1
bsf ecx, ebp ; garbage block 1
lea rbp, [rdi+523EE0D9h] ; garbage block 1
stc ; garbage block 1
xchg eax, r13d ; garbage block 1
or ecx, 746C1756h ; garbage block 1
lea rsi, [rsi+1] ; garbage block 1
pop rax ; handler logic
movzx rax, byte ptr [rax] ; handler logic
push rax ; handler logic
btc r13w, di ; garbage block 2
bsf ecx, ebp ; garbage block 2
clc ; garbage block 2
or esi, 71236376h ; garbage block 2
mov rsi, [r8] ; next handler decryption
add r8, 8 ; next handler decryption
xor rsi, r10 ; next handler decryption
ror rsi, 1Ah ; next handler decryption
xor r10, rsi ; next handler decryption
jmp rsi
VM_READ8_122 endp
The first block can only be 3 to 10 garbage instructions long, while the second one can only be 2 to 4. This instructions do not interfere with stack, nor do they change registers used during vm execution.
VM instruction set
Besides VM Entry and VM Exit, there are only 9 virtual instructions.
VM_PUSH_VREG
This instruction pushes virtual register onto the stack.
mov rdi, [r8] ; read encrypted register index
add r8, 8
xor rdi, r10 ; decrypt virtual register index
ror rdi, 8 ; decrypt virtual register index
xor r10, rdi ; update rolling key register
push qword ptr [r9+rdi*8] ; push virtual register
VM_POP_VREG
This instruction pops virtual register from the stack.
mov rdx, [r8]
add r8, 8
xor rdx, r10
ror rdx, 1Ah
xor r10, rdx
pop qword ptr [r9+rdx*8]
VM_PUSH_CONST
This instruction decrypts and pushes 64-bit value onto the stack.
mov rbp, [r8]
add r8, 8
xor rbp, r10
ror rbp, 19h
xor r10, rbp
push rbp
VM_READ_8
This instruction pops memory address from stack, reads 8-bit value from it and pushes it onto the stack as a 64-bit value.
pop rax
movzx rax, byte ptr [rax]
push rax
VM_READ_64
Same as the previous one but reads full 64-bit value.
pop rax
mov rax, [rax]
push rax
VM_ADD
This instruction pops 2 values from stack, adds them together and pushes result back.
pop rax
pop rbx
add rax, rbx
push rax
VM_NAND
This instruction performs logical NAND on 2 values on the stack.
pop rax
pop rbx
and rax, rbx
not rax
push rax
VM_MUL
This instruction performs 64-bit multiplication on 2 values on the stack.
pop rax
pop rbx
mul rbx
push rax
VM_JNZ
The VM_JNZ instruction changes vm execution depending on comparison of 2 values on the stack. In order to successfully jump to a different bytecode location, vm must know:
- New bytecode address
- New rolling key
- New ror shift key
Hence we see 5 pops:
pop rax ; arg 1
pop rbx ; arg 2
pop rdx ; new rolling key
pop rdi ; new new bytecode address
pop rsi ; new ror shift key
cmp rax, rbx ; arg 1 == arg 2 ?
mov rcx, 13h
cmovnz r10, rdx
cmovnz r8, rdi
cmovnz rcx, rsi
mov rax, [r8]
add r8, 8
xor rax, r10
ror rax, cl ; decrypt next handler or jmp target handler
xor r10, rax
push rax
retn
Note, that vm does not have XOR, AND, OR. All those operations are performed through VM_NAND virtual instruction. E.g. consider the following virtual instruction stream:
VM_PUSH_VREG 2
VM_PUSH_VREG 2
VM_PUSH_VREG 0
VM_PUSH_VREG 0
VM_PUSH_VREG 2
VM_PUSH_VREG 0
VM_NAND
VM_NAND
VM_POP_VREG 0
VM_NAND
VM_NAND
VM_PUSH_VREG 0
VM_NAND
VM_POP_VREG 0
This is an equivalent of r0 = ~(~(~(r0 & r2) & r0) & ~(~(r0 & r2) & r2)) which is r0 = r0 ^ r2.
AsmJit
“AsmJit is a lightweight library for machine code generation written in C++ language. It can generate machine code for X86 and X86_64 architectures with the support for the whole instruction set - from legacy MMX to the newest AVX-512 and AMX.” (https://asmjit.com/)
Why do we care about asmjit? AsmJit allows us to describe virtual architecture in a high level language (like c++) and compile it back to x86 at runtime. It also has a built in register allocator so you can create as many virtual registers as you want. Consider the following example:
#include <asmjit/asmjit.h>
using namespace asmjit;
typedef int (*function)(int, int);
int jit_add(int a, int b)
{
JitRuntime rt;
CodeHolder code;
code.init(rt.environment());
// Enable logging
FileLogger logger(stdout);
logger.setFlags(
FormatOptions::Flags::kFlagAnnotations |
FormatOptions::Flags::kFlagDebugPasses |
FormatOptions::Flags::kFlagDebugRA |
FormatOptions::Flags::kFlagHexImms |
FormatOptions::Flags::kFlagHexOffsets
);
code.setLogger(&logger);
x86::Compiler cc(&code);
// Create int func(int, int)
cc.addFunc(FuncSignatureT<int, int, int>());
// Create 2 virtual registers
x86::Gp a_reg = cc.newInt32("a");
x86::Gp b_reg = cc.newInt32("b");
// Assign function arguments
cc.setArg(0, a_reg);
cc.setArg(1, b_reg);
// Emit function body
cc.add(a_reg, b_reg);
cc.ret(a_reg);
// End function body and compile
cc.endFunc();
cc.finalize();
function fn;
rt.add(&fn, &code);
// Execute function
return fn(a, b);
}
int main()
{
std::printf("%d\n", jit_add(5, 10));
}
Sure enough it will print 15, but what if we wanted to dump compiled code? It is as easy as:
auto dump = code.sectionById(0)->buffer();
std::ofstream of("dump", std::ios::out | std::ios::binary);
of.write((const char*)dump.data(), dump.size());
And this is how it will look like in IDA:
seg000:0000000000000000
seg000:0000000000000000 sub_0 proc near
seg000:0000000000000000 add ecx, edx
seg000:0000000000000002 mov eax, ecx
seg000:0000000000000004 retn
seg000:0000000000000004 sub_0 endp
seg000:0000000000000004
seg000:0000000000000004 seg000 ends
seg000:0000000000000004
Before reaching x86 assembly, AsmJit has to map our a_reg and b_reg to physical registers like rax, rbx, rcx etc. Enabling logging reveals all internal workings of register allocation pass which is the only pass that is present by default:
[RAPass::BuildCFG]
L1: i32@eax Func(i32@ecx a, i32@edx b)
{#0}
add a, b
[FuncRet] a
{#1}
L0:
[FuncEnd]
[RAPass::BuildViews]
#0 -> {#1}
#1 -> {Exit}
[RAPass::BuildDominators]
IDom of #1 -> #0
Done (2 iterations)
[RAPass::BuildLiveness]
LiveIn/Out Done (4 visits)
{#0}
IN [a, b]
GEN [a, b]
{#1}
a {id:0256 width: 3 freq: 0.6667 priority=0.6767}: [2:5]
b {id:0257 width: 1 freq: 1.0000 priority=1.0100}: [2:3]
[RAPass::BinPack] Available=15 (0x0000FFEF) Count=2
01: [2:5@256]
02: [2:3@257]
Completed.
[RAPass::Rewrite]
.section .text {#0}
L1:
add ecx, edx ; add a, b | a{X|Use} b{R|Use|Last|Kill}
mov eax, ecx ; <MOVE> a
L0: ; L0:
ret
VM Analysis
Before we can perform any analysis, we must be able to follow vm execution. To do so we have to:
- Find ror shift value of every decryption routine
- Properly decrypt next handler address and update rolling key value
For the first step I used zydis disassembler and pattern matching. Since every decryption block starts with xor value, rkey and ends with xor rkey, value we can easily locate every ror shift value in a virtual instruction handler:
std::vector<uint64_t> extract_ror_keys(const x86::routine_t& routine)
{
std::vector<uint64_t> out;
int from = 0;
// Pattern matcher for "ror reg, value"
auto f_ror = [&](const x86::zydis_instruction_t& instr) -> bool
{
return instr.mnemonic == ZYDIS_MNEMONIC_ROR &&
instr.operands[0].type == ZYDIS_OPERAND_TYPE_REGISTER &&
instr.operands[1].type == ZYDIS_OPERAND_TYPE_IMMEDIATE;
};
while (true)
{
// Find pattern
from = routine.next(f_ror, from);
if (from == -1)
break;
assert(from < routine.size() - 1);
assert(from > 0);
// Check if before and after instructions are xor
const auto& before = routine[(size_t)from - 1].instr;
const auto& after = routine[(size_t)from + 1].instr;
if (before.mnemonic == ZYDIS_MNEMONIC_XOR &&
after.mnemonic == ZYDIS_MNEMONIC_XOR)
{
out.push_back(routine[from].instr.operands[1].imm.value.u);
}
from++;
}
return out;
}
The function above wont find ror rax, cl in VM_JNZ hanlder, so we have to make some adjustments:
uint64_t extact_jcc_key(const x86::routine_t& routine)
{
// Pattern matcher for "ror rax, cl"
auto f_ror = [&](const x86::zydis_instruction_t& instr) -> bool
{
return instr.mnemonic == ZYDIS_MNEMONIC_ROR &&
instr.operands[0].type == ZYDIS_OPERAND_TYPE_REGISTER &&
instr.operands[0].reg.value == ZYDIS_REGISTER_RAX &&
instr.operands[1].type == ZYDIS_OPERAND_TYPE_REGISTER &&
instr.operands[1].reg.value == ZYDIS_REGISTER_CL;
};
// Pattern matcher for "mov rcx, value"
auto f_load = [&](const x86::zydis_instruction_t& instr) -> bool
{
return instr.mnemonic == ZYDIS_MNEMONIC_MOV &&
instr.operands[0].type == ZYDIS_OPERAND_TYPE_REGISTER &&
instr.operands[0].reg.value == ZYDIS_REGISTER_RCX &&
instr.operands[1].type == ZYDIS_OPERAND_TYPE_IMMEDIATE;
};
// Check if decryption present
auto i_ror = routine.prev(f_ror);
assert(i_ror != -1);
// Find last rcx load
auto i_load = routine.prev(f_load, i_ror);
assert(i_load != -1);
// return ror key value
return routine[i_load].instr.operands[1].imm.value.u;
}
The second step is trivial since decryption only depends on ror shift value:
uint64_t state::decrypt_vip(uint64_t ror_key)
{
// Read bytecode value
auto v = *reinterpret_cast<uint64_t*>(vip);
// Advance bytecode ptr
vip += sizeof(vip);
v = v ^ rkey; // xor v, rkey
v = _rotr64(v, (int)ror_key); // ror v, ror_key
rkey ^= v; // xor rkey, v
return v;
}
With that out of the way we can now step through vm bytecode and analyze every handler. Despite handler obfuscation, actual handler logic stays the same. Because of this we can use pattern matching again to identify every vm handler.
I wont list every pattern for every instruction (You can check my github repo), but just to give an example here is how VM_READ_64 handler pattern looks like:
/*
* pop rax
* mov rax, [rax]
* push rax
*/
opcodes::Read64,
{
[](const state& state, const x86::routine_t& routine) -> bool
{
return routine.next([&](const x86::zydis_instruction_t& instr) -> bool
{
return instr.mnemonic == ZYDIS_MNEMONIC_MOV &&
instr.operands[1].type == ZYDIS_OPERAND_TYPE_MEMORY &&
instr.operands[1].mem.base == ZYDIS_REGISTER_RAX &&
instr.operands[0].reg.value == ZYDIS_REGISTER_RAX;
}
) != -1;
},
[](state& state, instruction_t& instr)
{
}
}
And with that we can dump whole routine:
0x140067050 VM_POP_VREG 0xd
0x140067060 VM_POP_VREG 0x1
0x140067070 VM_POP_VREG 0x5
0x140067080 VM_POP_VREG 0x8
0x140067090 VM_POP_VREG 0x2
0x1400670a0 VM_POP_VREG 0x0
0x1400670b0 VM_POP_VREG 0xb
0x1400670c0 VM_POP_VREG 0x4
0x1400670d0 VM_POP_VREG 0x6
0x1400670e0 VM_POP_VREG 0x3
0x1400670f0 VM_POP_VREG 0xa
0x140067100 VM_POP_VREG 0x9
0x140067110 VM_POP_VREG 0x7
0x140067120 VM_POP_VREG 0xe
0x140067130 VM_POP_VREG 0xc
...
0x140067200 VM_PUSH_CONST 0x8
0x140067210 VM_PUSH_CONST 0x140067200
0x140067220 VM_PUSH_CONST 0x1337deac296bdc7f
0x140067230 VM_PUSH_CONST 0x27
0x140067240 VM_PUSH_VREG 0x7
0x140067250 VM_PUSH_CONST 0xbc
...
0x1400672b8 VM_PUSH_CONST 0x13
0x1400672c8 VM_PUSH_CONST 0x14006720d
0x1400672d8 VM_PUSH_CONST 0xa97c6dea737dd37
0x1400672e8 VM_PUSH_CONST 0x0
0x1400672f8 VM_PUSH_VREG 0xe
0x140067308 VM_JNZ 0x14006720d
...
0x140067370 VM_PUSH_CONST 0x17
0x140067380 VM_PUSH_CONST 0x140067245
0x140067390 VM_PUSH_CONST 0x37d1988ec8e64eb2
0x1400673a0 VM_PUSH_CONST 0xffffffffffffffff
0x1400673b0 VM_PUSH_VREG 0xe
0x1400673c0 VM_JNZ 0x140067245
... ~120 instructions later
0x1400678f0 VM_PUSH_VREG 0x3
0x140067900 VM_NAND 0x0
0x140067908 VM_POP_VREG 0x6
0x140067918 VM_NAND 0x0
0x140067920 VM_PUSH_VREG 0x6
0x140067930 VM_NAND 0x0
0x140067938 VM_POP_VREG 0xc
0x140067948 VM_ADD 0x0
0x140067950 VM_POP_VREG 0x7
0x140067960 VM_PUSH_VREG 0x7
0x140067970 VM_JNZ 0x140067200
0x140067978 VM_POP_VREG 0x6
0x140067988 VM_POP_VREG 0x3
0x140067998 VM_POP_VREG 0xa
0x1400679a8 VM_POP_VREG 0xe
0x1400679b8 VM_POP_VREG 0x7
0x1400679c8 VM_POP_VREG 0x9
0x1400679d8 VM_PUSH_VREG 0xc
0x1400679e8 VM_PUSH_VREG 0xe
0x1400679f8 VM_PUSH_VREG 0x7
0x140067a08 VM_PUSH_VREG 0x9
0x140067a18 VM_PUSH_VREG 0xa
0x140067a28 VM_PUSH_VREG 0x3
0x140067a38 VM_PUSH_VREG 0x6
0x140067a48 VM_PUSH_VREG 0x4
0x140067a58 VM_PUSH_VREG 0xb
0x140067a68 VM_PUSH_VREG 0x0
0x140067a78 VM_PUSH_VREG 0x2
0x140067a88 VM_PUSH_VREG 0x8
0x140067a98 VM_PUSH_VREG 0x5
0x140067aa8 VM_PUSH_VREG 0x1
0x140067ab8 VM_PUSH_VREG 0xd
0x140067ac8 VM_EXIT 0x0
As you can see this function has 3 VM_JNZ instructions. The first 2 jumps do not make any sence because every entry in bytecode is 8 byte aligned and they jump to 0x14006720d and 0x140067245 respectively. If we ever take those branches we will crash (And this is intentional). But the third jump looks more like a loop.
To summarize: the function has 1 loop at 0x140067970 and 2 dead branches.
Note that vm pops all physical registers into virtual ones right after VM Entry and pushes all virtual registers right before VM Exit. This is what I meant by “1 to 1 mapping between physical and virtual registers”.
JIT compilation (attempt 1)
Now that we can follow vm execution and match handlers, we can try to compile them back to x86 with the help of AsmJit.
Since our vm extensively uses stack to store temporary arguments we should do the same in our jit. It is important to note that with asmjit::x86::Compiler we cannot use real stack since it uses the stack to spill registers, etc… For our purposes AsmJit allows us to make “new stack”.
// Create new stack
//
stack = cc->newStack(0x1000, 8, "Virtual Stack");
idx = cc->newIntPtr("Idx");
stack.setIndex(idx);
And corresponding virtual_push and virtual_pop instructions:
asmjit::x86::Gp jitter::virtual_pop()
{
// Create temp register
auto v = cc->newGpq();
// mov v, [stack + idx]
cc->mov(v, stack);
cc->add(idx, 8);
return v;
}
void jitter::virtual_push(asmjit::x86::Gp v)
{
// mov [stack + idx], v
cc->mov(stack, v);
cc->sub(idx, 8);
}
The implementation of every virtual insrtuction is simular and i’ll list just one to give you an idea:
{
vm::opcodes::Add,
[](const vm::instruction_t& instr, jitter& jit)
{
auto temp_r1 = jit.virtual_pop();
auto temp_r2 = jit.virtual_pop();
jit.cc->add(temp_r1, temp_r2);
jit.virtual_push(temp_r1);
}
},
Here’s how our jitted function will look like before compiler makes register allocation pass:
...
L37: // VM_PUSH_CONST
mov %52, 0x1400686E8
mov [&Virtual Stack+Idx], %52
sub Idx, 8
{#37}
L38: // VM_PUSH_VREG
mov %53, [&Virtual Stack+Idx]
add Idx, 8
mov %53, [%53]
mov [&Virtual Stack+Idx], %53
sub Idx, 8
{#38}
L39: // VM_ADD
mov %54, [&Virtual Stack+Idx]
add Idx, 8
mov %55, [&Virtual Stack+Idx]
add Idx, 8
add %54, %55
mov [&Virtual Stack+Idx], %54
sub Idx, 8
{#39}
...
For simplicity, every label contains one virtual instruction. And this is how recompiled function will look like:
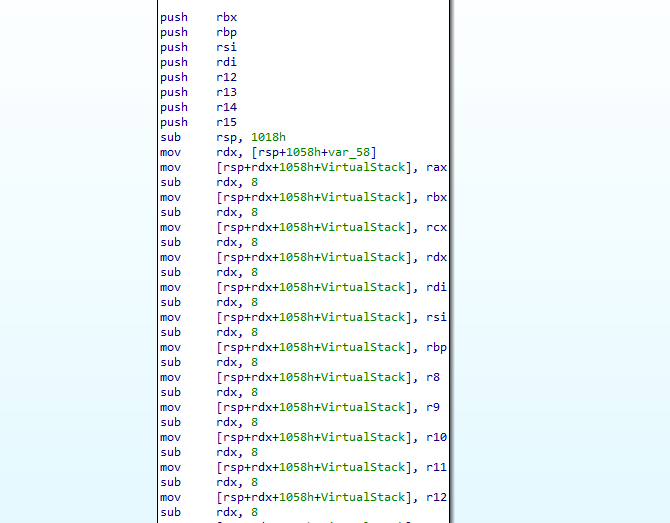
Not ideal, right? Thats because compiler is unable to optimize stack writes and remove/optimize unnecessary ones.
JIT compilation (attempt 2)
What if we didn’t use real stack at all but just a vector of virtual registers? Every time a handler would push something onto the stack we would instead push it into our vector and every time a handler would pop something from stack, we would pop it from vector.
The virtual instruction semantics will stay the same, but virtual_push and virtual_pop functions now look like this:
std::vector<asmjit::x86::Gp> stack;
asmjit::x86::Gp jitter::virtual_pop()
{
auto v = stack.back();
stack.pop_back();
return v;
}
void jitter::virtual_push(asmjit::x86::Gp v)
{
stack.push_back(v);
}
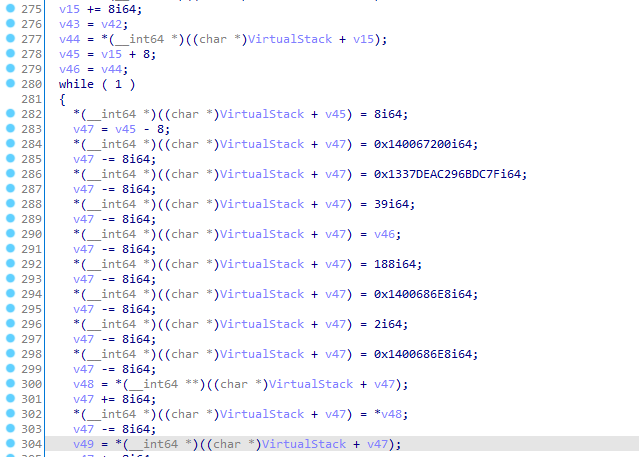
The function looks way cleaner now:
...
L30: // VM_PUSH_CONST
mov %25, 0x140067200
{#29}
L31: // VM_PUSH_CONST
mov %26, 0x1337DEAC296BDC7F
{#30}
L32: // VM_PUSH_CONST
mov %27, 0x27
{#31}
L33: // VM_PUSH_VREG
mov %28, %7
{#32}
L34: // VM_PUSH_CONST
mov %29, 0xBC
{#33}
...
Notice that there’s no stack accesses at all. We completely removed stack machine and its compilers job to allocate all those registers for us!
All we have to do now is to replace VM Entry with our newly compiled function. And this is what we get:
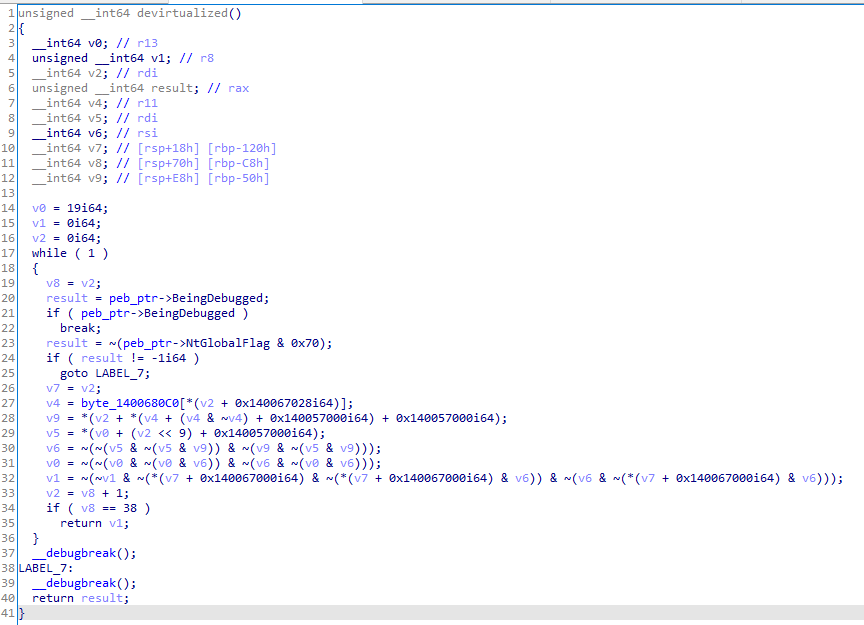
Remember those 2 dead branches? They are executed if debugger is present, no wonder they lead to program crash.
Solution
After some reversing we can see:
byte_1400680c0- contains user input array0x140067028- contains positions array0x140057000- contains 8 bit addition matrix, so0x140057000[i][j] == i + j(yet enother obfuscation technique).0x140067000- contains encoded flag array
With xor and or deobfuscation we end up with the following:
unsigned int devirtualized()
{
__int64 key; // r13
unsigned __int64 out; // r8
__int64 i; // rdi
unsigned __int64 result; // rax
__int64 v4; // r11
__int64 v5; // rdi
__int64 v6; // rsi
__int64 v7; // [rsp+18h] [rbp-120h]
__int64 v8; // [rsp+70h] [rbp-C8h]
__int64 v9; // [rsp+E8h] [rbp-50h]
key = 19;
out = 0;
i = 0;
while ( 1 )
{
v8 = i;
result = peb_ptr->BeingDebugged;
if ( peb_ptr->BeingDebugged )
break;
result = ~(peb_ptr->NtGlobalFlag & 0x70);
if ( result != -1i64 )
goto LABEL_7;
v7 = i;
v4 = input[positions[i]];
v9 = i + v4;
v5 = key + i * 2;
v6 = v5 ^ v9;
key = key ^ v6;
out = out | (v6 ^ encrypted[i]);
i = v8 + 1;
if ( v8 == 38 )
return out;
}
__debugbreak();
LABEL_7:
__debugbreak();
return result;
}
Full solution script:
positions = [
0x06, 0x12, 0x05, 0x0A, 0x0D, 0x13, 0x0E, 0x23, 0x18, 0x07,
0x20, 0x22, 0x1D, 0x0F, 0x04, 0x08, 0x03, 0x0B, 0x25, 0x15,
0x16, 0x1C, 0x01, 0x19, 0x1A, 0x1F, 0x10, 0x1E, 0x11, 0x17,
0x26, 0x21, 0x24, 0x09, 0x0C, 0x1B, 0x02, 0x00, 0x14
]
encoded_flag = [
0x47, 0x38, 0x35, 0x34, 0x16, 0xEF, 0xD9, 0x20, 0x44, 0x74,
0x18, 0x64, 0x4D, 0xF4, 0xDB, 0xEB, 0x42, 0x48, 0x46, 0x8F,
0xD7, 0x6F, 0x88, 0x09, 0x04, 0x1A, 0xCD, 0xF9, 0xCB, 0xA3,
0xD7, 0x82, 0xD4, 0xA6, 0xE0, 0x9F, 0x09, 0xF5, 0x85
]
res = [0 for _ in range(39)]
key = 0x13
for i in range(len(encoded_flag)):
res[positions[i]] = ((encoded_flag[i] ^ ((key + i * 2) & 0xFF)) - i) & 0xFF
key ^= encoded_flag[i]
print(''.join(list(map(chr, res))))
Full source code for this project can be found on my github repo here.
The end.