VaultVM

Mr. Smith has designed a digital vault for his important files and passwords. Seeing how many ASICs are being built to mine crypto he started questioning the strength of cryptographic hash algorithms so he decided to implement his own way to store the master password. Now he asks you to test it, offering a substantial reward if you can break in.
Author: avlad171
At first I didn’t want to reverse engineer the virtual machine and tried to cheese it with symbolic execution. But my tool could not propagate symbolic expressions for some reason. After that I changed symbolic engine to taint engine with pointer propagation and got some results:
address instruction memory operand tainted register r/w value
0xbaa: movzx eax, byte ptr [rax] 0x9fffff90 rax:64 bv[63..0] 0x58
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff38 rax:64 bv[63..0] 0x58
0xb2b: mov rdx, qword ptr [rsi + rcx*8] 0x9fffff38 rdx:64 bv[63..0] 0x58
0xb32: add qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0x58
0xba0: mov rax, qword ptr [rsi + rax*8] 0x9fffff70 rax:64 bv[63..0] 0x204638
0xbaa: movzx eax, byte ptr [rax] 0x204638 rax:64 bv[63..0] 0xa8
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff28 rax:64 bv[63..0] 0xa8
0xb2b: mov rdx, qword ptr [rsi + rcx*8] 0x9fffff28 rdx:64 bv[63..0] 0xa8
0xb32: add qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0xa8
0xba0: mov rax, qword ptr [rsi + rax*8] 0x9fffff70 rax:64 bv[63..0] 0x212788
0xbaa: movzx eax, byte ptr [rax] 0x212788 rax:64 bv[63..0] 0xa8
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff20 rax:64 bv[63..0] 0xa8
0xa3e: imul rax, qword ptr [rdx] 0x9fffff20 rax:64 bv[63..0] 0xa800
0xa42: mov qword ptr [rdx], rax 0x9fffff20 rax:64 bv[63..0] 0xa800
0xbaa: movzx eax, byte ptr [rax] 0x9fffff91 rax:64 bv[63..0] 0x2d
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff38 rax:64 bv[63..0] 0x2d
0xb2b: mov rdx, qword ptr [rsi + rcx*8] 0x9fffff38 rdx:64 bv[63..0] 0x2d
0xb32: add qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0x2d
0xba0: mov rax, qword ptr [rsi + rax*8] 0x9fffff70 rax:64 bv[63..0] 0x20e80d
0xbaa: movzx eax, byte ptr [rax] 0x20e80d rax:64 bv[63..0] 0xed
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff28 rax:64 bv[63..0] 0xed
0xc37: mov rdx, qword ptr [rsi + rdx*8] 0x9fffff20 rdx:64 bv[63..0] 0x21cee0
0xc3b: mov qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0x21cee0
0xb2b: mov rdx, qword ptr [rsi + rcx*8] 0x9fffff28 rdx:64 bv[63..0] 0xed
0xb32: add qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0xed
0xba0: mov rax, qword ptr [rsi + rax*8] 0x9fffff70 rax:64 bv[63..0] 0x21cfcd
0xbaa: movzx eax, byte ptr [rax] 0x21cfcd rax:64 bv[63..0] 0x95
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff20 rax:64 bv[63..0] 0x95
0xa3e: imul rax, qword ptr [rdx] 0x9fffff20 rax:64 bv[63..0] 0x9500
0xa42: mov qword ptr [rdx], rax 0x9fffff20 rax:64 bv[63..0] 0x9500
0xbaa: movzx eax, byte ptr [rax] 0x9fffff92 rax:64 bv[63..0] 0x4d
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff38 rax:64 bv[63..0] 0x4d
0xb2b: mov rdx, qword ptr [rsi + rcx*8] 0x9fffff38 rdx:64 bv[63..0] 0x4d
0xb32: add qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0x4d
0xba0: mov rax, qword ptr [rsi + rax*8] 0x9fffff70 rax:64 bv[63..0] 0x20582d
0xbaa: movzx eax, byte ptr [rax] 0x20582d rax:64 bv[63..0] 0xbd
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff28 rax:64 bv[63..0] 0xbd
0xc37: mov rdx, qword ptr [rsi + rdx*8] 0x9fffff20 rdx:64 bv[63..0] 0x21bbe0
0xc3b: mov qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0x21bbe0
0xb2b: mov rdx, qword ptr [rsi + rcx*8] 0x9fffff28 rdx:64 bv[63..0] 0xbd
0xb32: add qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0xbd
0xba0: mov rax, qword ptr [rsi + rax*8] 0x9fffff70 rax:64 bv[63..0] 0x21bc9d
0xbaa: movzx eax, byte ptr [rax] 0x21bc9d rax:64 bv[63..0] 0x52
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff20 rax:64 bv[63..0] 0x52
0xa3e: imul rax, qword ptr [rdx] 0x9fffff20 rax:64 bv[63..0] 0x5200
0xa42: mov qword ptr [rdx], rax 0x9fffff20 rax:64 bv[63..0] 0x5200
0xbaa: movzx eax, byte ptr [rax] 0x9fffff93 rax:64 bv[63..0] 0x41
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff38 rax:64 bv[63..0] 0x41
0xb2b: mov rdx, qword ptr [rsi + rcx*8] 0x9fffff38 rdx:64 bv[63..0] 0x41
0xb32: add qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0x41
0xba0: mov rax, qword ptr [rsi + rax*8] 0x9fffff70 rax:64 bv[63..0] 0x210421
0xbaa: movzx eax, byte ptr [rax] 0x210421 rax:64 bv[63..0] 0x1d
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff28 rax:64 bv[63..0] 0x1d
0xc37: mov rdx, qword ptr [rsi + rdx*8] 0x9fffff20 rdx:64 bv[63..0] 0x2178e0
0xc3b: mov qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0x2178e0
0xb2b: mov rdx, qword ptr [rsi + rcx*8] 0x9fffff28 rdx:64 bv[63..0] 0x1d
0xb32: add qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0x1d
0xba0: mov rax, qword ptr [rsi + rax*8] 0x9fffff70 rax:64 bv[63..0] 0x2178fd
0xbaa: movzx eax, byte ptr [rax] 0x2178fd rax:64 bv[63..0] 0x6f
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff20 rax:64 bv[63..0] 0x6f
0xa3e: imul rax, qword ptr [rdx] 0x9fffff20 rax:64 bv[63..0] 0x6f00
0xb32: add qword ptr [rsi + rax*8], rdx 0x9fffff70 rdx:64 bv[63..0] 0x18
0xba0: mov rax, qword ptr [rsi + rax*8] 0x9fffff70 rax:64 bv[63..0] 0x2195f8
0xbaa: movzx eax, byte ptr [rax] 0x2195f8 rax:64 bv[63..0] 0x87
0xbad: mov qword ptr [rsi + rdx*8], rax 0x9fffff20 rax:64 bv[63..0] 0x87
0xa3e: imul rax, qword ptr [rdx] 0x9fffff20 rax:64 bv[63..0] 0x8700
Now it somewhat doable, but after a few hours I gave up on this because it became way more complicated. So let’s start reverse engineering a virtual machine.
The binary cointains a virtual machine with 16 virtual registers and 28 instructions. The registers are decoded as follows:
r = bytecode[pc++];
reg_dst = (r & 0xF0) >> 4;
reg_src = r & 0xF;
The instruction set is rather simple:
VM_MOV
VM_XOR
VM_AND
VM_OR
VM_ADD
VM_SUB
VM_NOT
VM_ADD_IMM_8
VM_ADD_IMM_16
VM_ADD_IMM_32
VM_ADD_IMM_64
VM_MUL
VM_MUL_IMM_8
VM_MUL_IMM_16
VM_MUL_IMM_32
VM_MUL_IMM_64
VM_LOAD_8
VM_LOAD_16
VM_LOAD_32
VM_LOAD_64
VM_STR_8
VM_STR_16
VM_STR_32
VM_STR_64
VM_JNZ
VM_NOP
VM_EXIT
The dispatcher decrypts next handler and jumps to it:
movzx eax, al
movsxd rax, dword ptr [r8+rax*4]
xor eax, 13371337h
not eax
movsxd rax, eax
add rax, r8
jmp rax ; switch jump
Before vm enter, the registers are intialized with some values.
I used miasm to lift bytecode into my IR and then into miasm IR for further optimizations.
lifting to miasm IR is very simple:
def xor(ir, instr, arg):
e = []
src1, src2 = decode_regs(arg)
result = src1 ^ src2
e += [ExprAssign(src1, result)]
return e, []
def sub(ir, instr, arg):
e = []
dst, src = decode_regs(arg)
e += [ExprAssign(dst, dst - src)]
return e, []
So after all of this, I can now generate IRcfg of virtualized function:
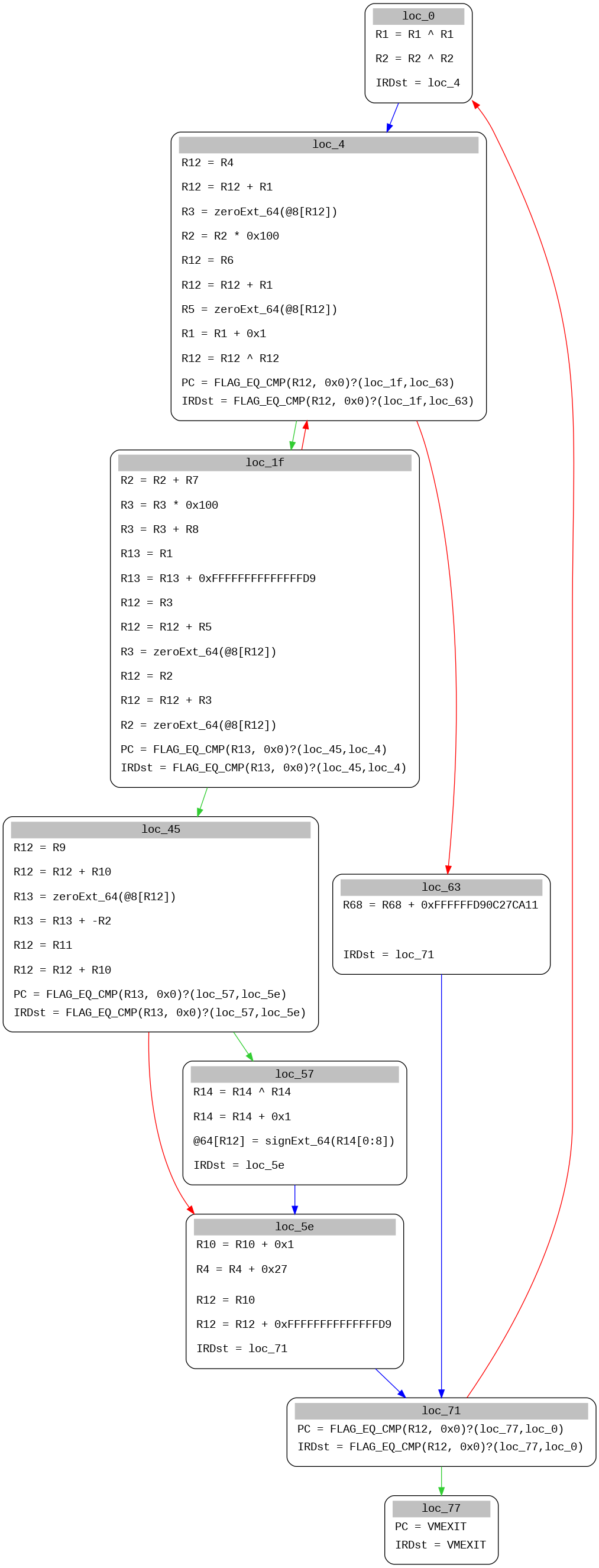
This code even has opaque predicate at loc_4!
Now we can use miasm standard features to optimize ircfg:
ira = machine.ira(loc_db)
ircfg = ira.new_ircfg_from_asmcfg(asmcfg)
loc = loc_db.get_offset_location(addr)
simp = IRCFGSimplifierCommon(ira)
simp.simplify(ircfg, loc)
save_ircfg(ircfg, "ircfg.dot")
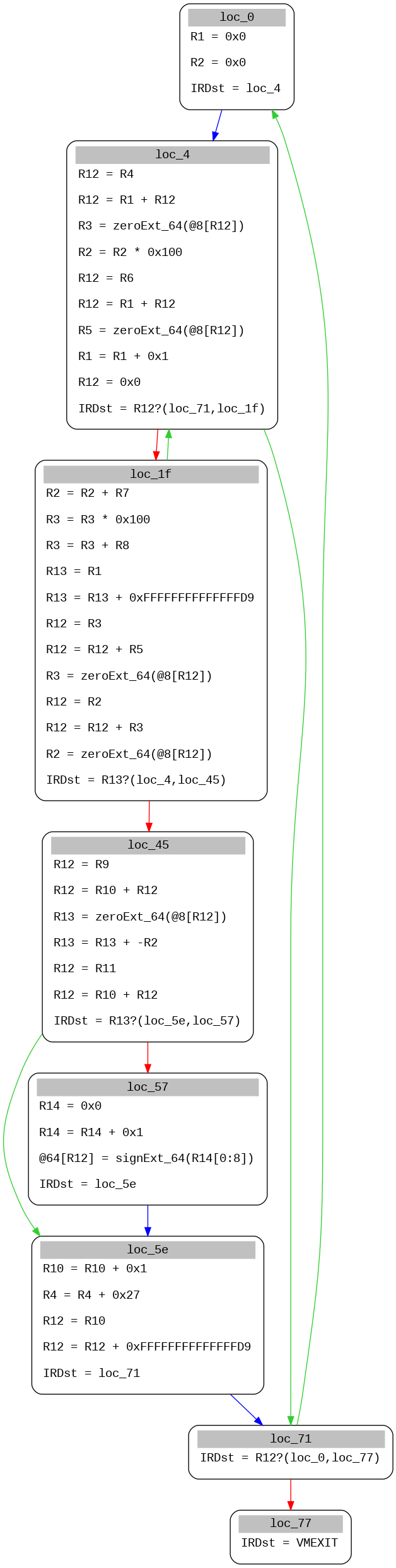
And easily translate it into original non virtualized function:
uint8_t *input;
uint8_t *flag;
uint8_t *sbox;
uint8_t *matrix1;
uint8_t *matrix2;
int main(){
uint8_t check = 1, t1, t2, t3;
for (int i = 0; i < 39; i++) {
uint8_t out = 0;
for (int j = 0; j < 39; j++) {
t1 = sbox[j];
t2 = matrix1[t1][input[j]]
out = matrix2[out][t2];
}
if (out != flag[i])
check = 0;
sbox += 39;
}
}
So now we know why my symbolic tracer failed to propagate expressions. Our input is used as an index in the array. If we look closely at matrix1 and matrix2 it will become clear that matrix1 is a multiplication matrix and matrix2 is a addition matrix. With that in mind, our source code will look like this:
uint8_t *input;
uint8_t *flag;
uint8_t *sbox;
int main(){
uint8_t check = 1;
for (int i = 0; i < 39; i++) {
uint8_t out = 0;
for (int j = 0; j < 39; j++) {
out += sbox[j] * input[j];
}
if (out != flag[i])
check = 0;
sbox += 39;
}
}
Now, it is a system of 39 equations and can be solved with sage in a few minutes. But I used z3 and got a flag in under an hour.
Here is the final solution:
from z3 import *
import sys
known = [ord(i) for i in 'X-MAS{']
def main():
raw = bytearray(open('vault', 'rb').read())
sbox = 0x020E0
flag = 0x020A0
s = Solver()
input = list()
for i in range(39):
c = BitVec('key_%d' % i, 8)
input.append(c)
s.add(c > 32, c < 127)
for i, v in enumerate(known):
s.add(input[i] == v)
s.add(input[-1] == ord('}'))
for j in range(39):
out = 0
for i in range(39):
out += raw[sbox + i] * input[i]
s.add(out & 0xff == raw[flag+j])
sbox += 39
if s.check() == sat:
m = s.model()
flag = ''
for i in range(39):
flag += chr(m[input[i]].as_long())
print(flag)
if __name__ == "__main__":
sys.exit(main())
And we get the flag!
X-MAS{m0dulO_eQuatioN_sYst3ms_arE_cO0L}
The end!