Реверс инжиниринг виртуальных машин с помощью Triton
В этой статье хотелось бы рассказать о подходе к реверсу вм, на примере одного задания с цтф.
Введение
Виртуализация - метод обфускации, при котором исходные инструкции программы преобразуются в код, понятный только интерпретатору, имитирующему виртуальную машину.
Символьное исполнение
Символьное исполнение - процесс “исполнения” программы, где конкретным значениям переменных сопоставляются символьные переменные. Последующие преобразования данных в программе описываются в виде формул над константами и символьными переменными. В каждой точке ветвления, зависящей от символьных переменных, происходит порождение функции, описывающей исполнение программы по определенному пути.
Предикат пути - система уравнений, построенная в результате символьного исполнения этого пути. Предикат пути подается на вход SMT-решателю, где в качестве неизвестных выступают символьные переменные. Решением системы уравнений предиката пути, является набор значений символьных переменных, обеспечивающий исполнение программы по этому пути.
Простыми словами, символьное исполнение помогает ответить на вопрос КАК программа дошла до определенной точки и КАК попасть в другие части программы.
Можно выделить 2 вида символьного исполнения:
- Статическое
- Динамическое
Static Symbolic Execution (SSE)
SSE - метод статического анализа, при которой код эмулируется, распространяя символьное состояние системы с каждой эмулированной инструкцией. Этот метод характерен тем, что он анализирует ВСЕ пути сразу.
Плюсы:
- Возможность исполнять код архитектуры, отличной от архитектуры хоста благодаря эмуляции.
- Возможность эмулирования произвольной последовательности инструкций (например одной функции), а не всей программы в целом.
Минусы:
- Анализ сразу двух путей при каждом ветвлении не всегда возможен из-за проблем с масштабированием.
- Некоторые части программы тяжело моделировать (например системные вызовы или вызовы библиотек)
Пример:
int check(int a, int b)
{
int c = a + b;
if (с > 100)
{
return 1;
}
return 0;
}
Пусть a и b - символьные переменные, phi(n) - n-ое выражение с символьными переменными, pi - предикат пути, sigma - набор символьных выражений, тогда функцию можно представить как:
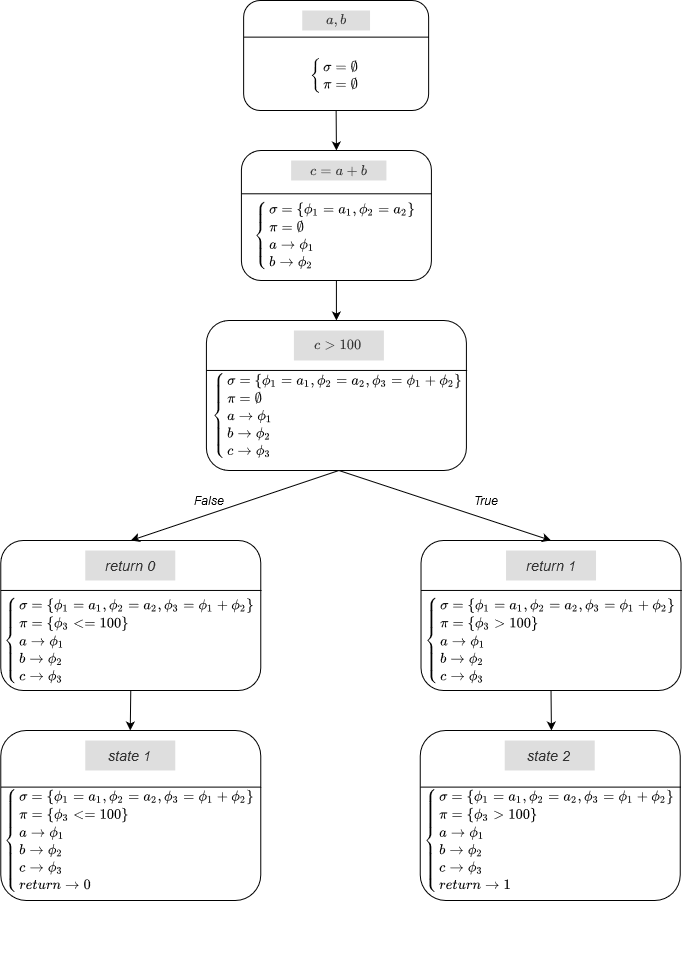
На выходе мы получаем 2 системы уравнений state 1 и state 2, решив которые, мы найдем значения переменных a и b для прохода обоих путей.
Отличный пример SSE - фреймворк angr.
Dynamic Symbolic Execution (DSE)
DSE - метод динамического анализа, при котором программа выполняется с заданными значениями переменных, а символьное состояние используется как дополнение к реальному. Из-за этого DSE обычно называют concolic execution (concrete symbolic execution). При DSE программа проходит один путь за раз. При необходимости найти другой путь, предикат пути инвертируется и подается SMT-решателю для нахождения переменных, удовлетворяющих новой системе уравнений.
Плюсы:
- Отличная масштабируемость, из-за выполнения 1 пути за раз.
- Меньшая сложность уравнений
Минусы:
- Скорость
Введение в Triton

Triton - Фреймворк для динамического анализа кода (DBA framework), в который входят такие инструменты как: движок для динамического символьного исполнения (DSE engine), движок для taint анализа (DTA engine), движок построения абстрактных синтаксических деревьев (AST) для x86, x86-64 и AArch64 архитектур, интерфейс для SMT-решателя. Triton также имеет Python-обвязку для своих библиотек.
Для понимания работы тритона лучше всего поможет код нахождения a и b из примера SSE:
from triton import *
import sys
'''
int check(int a, int b)
{
int c = a + b;
if (с > 100)
{
return 1;
}
return 0;
}
'''
function = {
0x5FA : b"\x55", # push rbp
0x5FB : b"\x48\x89\xE5", # mov rbp, rsp
0x5FE : b"\x89\x7D\xEC", # mov [rbp-14h], edi
0x601 : b"\x89\x75\xE8", # mov [rbp-18h], esi
0x604 : b"\x8B\x55\xEC", # mov edx, [rbp-14h]
0x607 : b"\x8B\x45\xE8", # mov eax, [rbp-18h]
0x60A : b"\x01\xD0", # add eax, edx
0x60C : b"\x89\x45\xFC", # mov [rbp-4], eax
0x60F : b"\x83\x7D\xFC\x64", # cmp dword ptr [rbp-4], 64h
0x613 : b"\x7E\x07", # jle short 0x61C
0x615 : b"\xB8\x01\x00\x00\x00", # mov eax, 1
0x61A : b"\xEB\x05", # jmp short 0x621
0x61C : b"\xB8\x00\x00\x00\x00", # mov eax, 0
0x621 : b"\x5D", # pop rbp
0x622 : b"\xC3" # retn
}
def main():
# Triton Context
ctx = TritonContext()
# Set Architecture
ctx.setArchitecture(ARCH.X86_64)
# Symbolic optimization
ctx.setMode(MODE.ALIGNED_MEMORY, True)
# Define the Python syntax
ctx.setAstRepresentationMode(AST_REPRESENTATION.PYTHON)
# set pc
pc = 0x5FA
# set a = 13
# set b = 37
ctx.setConcreteRegisterValue(ctx.registers.edi, 13)
ctx.setConcreteRegisterValue(ctx.registers.esi, 37)
# symbolize a and b
ctx.symbolizeRegister(ctx.registers.edi)
ctx.symbolizeRegister(ctx.registers.esi)
# emulate the function
while pc in function:
# Build an instruction
inst = Instruction()
# Setup opcode
inst.setOpcode(function[pc])
# Setup Address
inst.setAddress(pc)
# Process the instruction
ctx.processing(inst)
# Print only instructions that are symbolic
if inst.isSymbolized():
print('[symbolic instruction] %s' %(str(inst)))
# Next instruction
pc = ctx.getConcreteRegisterValue(ctx.registers.rip)
if __name__ == "__main__":
sys.exit(main())
Получаем такой вывод:
[symbolic instruction] 0x5fe: mov dword ptr [rbp - 0x14], edi
[symbolic instruction] 0x601: mov dword ptr [rbp - 0x18], esi
[symbolic instruction] 0x604: mov edx, dword ptr [rbp - 0x14]
[symbolic instruction] 0x607: mov eax, dword ptr [rbp - 0x18]
[symbolic instruction] 0x60a: add eax, edx
[symbolic instruction] 0x60c: mov dword ptr [rbp - 4], eax
[symbolic instruction] 0x60f: cmp dword ptr [rbp - 4], 0x64
[symbolic instruction] 0x613: jle 0x61c
Оно и понятно, вывелись все инструкции, которые как-то взаимодействует / зависят от символьных переменных.
Круто, при значениях a = 13 и b = 37 функция возвращает 0 (кэп). Давайте теперь попробуем найти такие значения переменных a > 100 и b > 100, при которых тоже вернется 0.
Для этого возьмем предикат пути, при котором возвращается 0 и добавим условие, что переменные должны быть > 100.
pco = ctx.getPathPredicate()
ast = ctx.getAstContext()
a = ast.variable(ctx.getSymbolicVariable(0))
b = ast.variable(ctx.getSymbolicVariable(1))
model = ctx.getModel(ast.land([pco, a > 100, b > 100]))
for k, v in sorted(model.items()):
print(k, v)
И получаем интересный результат:
0 SymVar_0:32 = 0xFFFFFFF3
1 SymVar_1:32 = 0x65
Тритон нашел значения a и b, при которых происходит переполнение переменной типа int и возвращается 0. Поскольку 32 битная переменная “c“ вычисляется как сумма двух 32 битных значений, переполнение имеет место быть. c = 0xFFFFFFF3 + 0x65 = 0x58
Этот пример отлично иллюстрирует силу Тритона и символьного исполнения. Заинтересовавшимся читателям рекомендую посмотреть примеры и документацию.
Далее будут расмотрен пример с виртуальной машиной и подход к его решению с помощью тритона. Для анализа виртуальных машин я использую трассировщик с подключенным DSE движком. В качестве трассировщика отлично подходит DynamoRIO или Intel PIN, для DSE - Triton, но из-за объема статьи сегодня мы обойдемся одним Тритоном. Виртуальную машину можно представить как черный ящик, на вход которого подаются данные, а на выходе выдается результат.
Пример
$ ./task
Welcome to SECURINETS CTF!
Give me the magic:test
No...
Этот таск был на квалификационном цтф securinets 2020, и из ~500 команд был решен всего 12 раз.
Сам таск состоит из 1 эльф файла с простой реализацией виртуальной машины - массив байткода, обработчика, виртуальных регистров и памяти.
Порядок выполнения вм:
void main()
{
int opcode;
while ( next )
{
++count;
opcode = fetch_opcode();
process_opcode(opcode);
}
}
Функция process_opcode содержит большой свитч (порядка 20 кейсов) анализ которой займет очень много времени.
Решение: Проэмулировать вм в тритоне и символьно достать правильное решение. Поскольку тритон не имеет понятия о эльфах и ос, нам необходимо описать это для него.
Для начала инициализируем Тритон:
ctx = TritonContext()
ctx.setArchitecture(ARCH.X86)
ctx.setMode(MODE.ALIGNED_MEMORY, True)
ctx.setMode(MODE.ONLY_ON_SYMBOLIZED, True)
ctx.setAstRepresentationMode(AST_REPRESENTATION.PYTHON)
Теперь с помощью LIEF расположим эльф в памяти:
def loadBinary(ctx, binary):
phdrs = binary.segments
for phdr in phdrs:
size = phdr.physical_size
vaddr = phdr.virtual_address
print('[+] Loading 0x%08x - 0x%08x' %(vaddr, vaddr+size))
ctx.setConcreteMemoryAreaValue(vaddr, phdr.content)
return
binary = lief.parse(sys.argv[1])
loadBinary(ctx, binary)
Перед эмулированием необходимо конкретизировать памяти и регистры, иначе тритон будет считать их символьными с самого начала. Так же нужно указать стэк.
BASE_STACK = 0x9fffffff
def run(ctx, binary):
# Concretize context
ctx.concretizeAllMemory()
ctx.concretizeAllRegister()
# Define a fake stack
ctx.setConcreteRegisterValue(ctx.registers.ebp, BASE_STACK)
ctx.setConcreteRegisterValue(ctx.registers.esp, BASE_STACK)
# Let's emulate the binary from the entry point
print('[+] Starting emulation.')
emulate(ctx, binary.entrypoint)
print('[+] Emulation done.')
return
Простая функция эмулирования:
# Emulate the binary.
def emulate(ctx, pc):
count = 0
while pc:
# Fetch opcodes
opcodes = ctx.getConcreteMemoryAreaValue(pc, 16)
# Create the Triton instruction
instruction = Instruction()
instruction.setOpcode(opcodes)
instruction.setAddress(pc)
# Process
if ctx.processing(instruction) == False:
debug('[-] Instruction not supported: %s' %(str(instruction)))
break
count += 1
# Get next pc
pc = ctx.getConcreteRegisterValue(ctx.registers.eip)
print('[+] Instruction executed: %d' %(count))
return
Запускаем ии.. ничего не происходит. А все потому, что у нас нет обработчиков libc функций. Тритон просто будет крашиться, когда вызывается что-нибудь из PLT секции. К счастью в нашем случае программа имеет всего 4 импорта и нам не составит труда их написать:
- __libc_start_main
- printf
- strlen
- __isoc99_scanf
Я опущу описание реализации __libc_start_main и начну сразу с важного - __isoc99_scanf.
В этой функции программа берет наш ввод и обрабатывает его, поэтому именно в этом месте мы будем символизировать память.
sym_input = list()
# Simulate the scanf() function
def scanfHandler(ctx):
global sym_input
print('[+] scanf hooked')
message = "test"
# Get buffer loc
stack_mem = MemoryAccess(ctx.getConcreteRegisterValue(ctx.registers.esp) + 8, 4)
str_loc = ctx.getConcreteMemoryValue(stack_mem)
# Fill scanf buffer with dummy inputs
ctx.setConcreteMemoryAreaValue(str_loc, message.encode() + b'\x00')
# Symbolize
print('[+] symbolizing scanf buffer')
for index in range(len(message)):
var = ctx.symbolizeMemory(MemoryAccess(arg2 + index, CPUSIZE.BYTE))
var.setComment("input_%d" % index)
sym_input.append(var)
# Return value
return (len(message), CONCRETE)
По такому же принципу напишем обработчик strlen:
# Simulate the strlen() function
def strlenHandler(ctx):
debug('[+] strlen hooked')
# Get arguments
str_loc = ctx.getConcreteMemoryValue(MemoryAccess(ctx.getConcreteRegisterValue(ctx.registers.esp) + 4, CPUSIZE.DWORD))
arg1 = getMemoryString(ctx, str_loc)
# Return value
if ctx.isMemorySymbolized(str_loc):
print('[+] symbolizing strlen')
return (len(arg1), SYMBOLIC)
else:
return (len(arg1), CONCRETE)
Замечу, что если память, указанная в аргументе символьная, вывод strlen тоже должен быть символьным.
Так же в функции emulate добавим строчку:
if instruction.isSymbolized():
print(instruction)
Запустим:
$ python3 solve-vm.py task
[+] Loading 0x8048034 - 0x8048154
[+] Loading 0x8048154 - 0x8048167
[+] Loading 0x8048000 - 0x8048fb4
[+] Loading 0x804ad38 - 0x804b212
[+] Loading 0x804af10 - 0x804aff8
[+] Loading 0x8048168 - 0x80481ac
[+] Loading 0x8048de8 - 0x8048e44
[+] Loading 0x000000 - 0x000000
[+] Loading 0x804ad38 - 0x804b000
[+] Hooking printf
[+] Hooking strlen
[+] Hooking __libc_start_main
[+] Hooking __isoc99_scanf
[+] Starting emulation.
[+] __libc_start_main hooked
[+] printf hooked
Welcome to SECURINETS CTF!
[+] printf hooked
Give me the magic:[+] scanf hooked
[+] symbolizing scanf buffer
[+] strlen hooked
[+] symbolizing strlen
0x8048978: mov edx, eax
0x8048980: mov dword ptr [eax], edx
0x80489a9: mov eax, dword ptr [eax + edx*4]
0x80489ac: mov dword ptr [ebp - 0x24], eax
0x80489ce: mov eax, dword ptr [ebp - 0x24]
0x80489d1: cmp eax, dword ptr [ebp - 0x20]
0x80489d4: jne 0x80489e8
[+] printf hooked
No...
[-] Instruction not supported: 0x8048422: hlt
[+] Instruction executed: 1166
[+] Emulation done.
Видно, что идет проверка длины нашей строки с каким-то значением из памяти, после чего сразу программа завершается с сообщением No....
Давайте достанем это значение:
if instruction.isSymbolized():
print(instruction)
if instruction.getAddress() == 0x80489d1:
ebp = ctx.getConcreteRegisterValue(ctx.registers.ebp)
mem = MemoryAccess(ebp - 0x20, 4)
val = ctx.getConcreteMemoryValue(mem)
print('[+] dword [ebp - 0x20] = %s' % hex(val))
Запускаем:
[+] symbolizing strlen
0x8048978: mov edx, eax
0x8048980: mov dword ptr [eax], edx
0x80489a9: mov eax, dword ptr [eax + edx*4]
0x80489ac: mov dword ptr [ebp - 0x24], eax
0x80489ce: mov eax, dword ptr [ebp - 0x24]
0x80489d1: cmp eax, dword ptr [ebp - 0x20]
[+] dword [ebp - 0x20] = 0x20
0x80489d4: jne 0x80489e8
[+] printf hooked
No...
Значит длина нашей строки должна быть 32 байта. Окей, поменяем в scanf обработчике message = "a" * 32.
$ python3 solve-vm.py task
[+] Loading 0x8048034 - 0x8048154
[+] Loading 0x8048154 - 0x8048167
[+] Loading 0x8048000 - 0x8048fb4
[+] Loading 0x804ad38 - 0x804b212
[+] Loading 0x804af10 - 0x804aff8
[+] Loading 0x8048168 - 0x80481ac
[+] Loading 0x8048de8 - 0x8048e44
[+] Loading 0x0000000 - 0x0000000
[+] Loading 0x804ad38 - 0x804b000
[+] Hooking printf
[+] Hooking strlen
[+] Hooking __libc_start_main
[+] Hooking __isoc99_scanf
[+] Starting emulation.
[+] __libc_start_main hooked
[+] printf hooked
Welcome to SECURINETS CTF!
[+] printf hooked
Give me the magic:[+] scanf hooked
[+] symbolizing scanf buffer
[+] strlen hooked
[+] symbolizing strlen
0x8048978: mov edx, eax
0x8048980: mov dword ptr [eax], edx
0x80489a9: mov eax, dword ptr [eax + edx*4]
0x80489ac: mov dword ptr [ebp - 0x24], eax
0x80489ce: mov eax, dword ptr [ebp - 0x24]
0x80489d1: cmp eax, dword ptr [ebp - 0x20]
0x80489d4: jne 0x80489e8
0x8048b8d: movzx ecx, byte ptr [eax]
0x8048b9d: xor ecx, ebx
0x8048b9f: mov edx, ecx
0x8048ba1: mov byte ptr [eax], dl
0x8048c4f: mov eax, dword ptr [eax + edx*4]
0x8048c52: mov dword ptr [ebp - 0x20], eax
0x8048c58: cmp eax, dword ptr [ebp - 0x20]
0x8048c5b: jne 0x8048c6c
...
...
...
0x80489ac: mov dword ptr [ebp - 0x24], eax
0x80489ce: mov eax, dword ptr [ebp - 0x24]
0x80489d1: cmp eax, dword ptr [ebp - 0x20]
0x80489d4: jne 0x80489e8
[+] printf hooked
Just get out ; No place for you here!
[-] Instruction not supported: 0x8048422: hlt
[+] Instruction executed: 32834
[+] Emulation done.
В этот раз мы выполнили почти 33к инструкций и получили совсем другое сообщение.
По трассе можно увидеть, что после проверки длины происходит преобразование нашего ввода. Теперь, чтобы найти новые решения, нужно собрать предикат пути и инвертировать его условия. Для этого я взял уже имеющуюся функцию из примеров тритона и добавил условия, что переменные из списка sym_input должны быть > 32 и < 127 (печатные символы из таблицы ascii):
def getNewInputs(ctx):
inputs = list()
ast = ctx.getAstContext()
pco = ctx.getPathConstraints()
# start with any input
previousConstraints = ast.equal(ast.bvtrue(), ast.bvtrue())
# Go through the path constraints
for pc in pco:
# If there is a condition
if pc.isMultipleBranches():
# Get all branches
branches = pc.getBranchConstraints()
for branch in branches:
# Get constraints of the branch which has been not taken
if not branch['isTaken']:
# Ask for model
models = ctx.getModel(ast.land(
[previousConstraints] +
[branch['constraint']] +
[ast.variable(i) > 32 for i in sym_input] +
[ast.variable(i) < 127 for i in sym_input]))
seed = dict()
for k, v in sorted(models.items()):
# Get symbolic variable assigned to model
symVar = ctx.getSymbolicVariable(k)
# Save new input
seed.update({symVar: v.getValue()})
if seed:
inputs.append(seed)
# Update the previous constraints with true branch to keep a good path
previousConstraints = ast.land([previousConstraints, pc.getTakenPredicate()])
return inputs
а в функции emulate:
...
...
...
print('[+] Getting new inputs..')
for input in getNewInputs(ctx):
out = ''
for k, v in input.items():
out += chr(v)
print(out)
return
И мы получаем флаг:
...
...
0x80489d4: jne 0x80489e8
[+] printf hooked
Just get out ; No place for you here!
[-] Instruction not supported: 0x8048422: hlt
[+] Instruction executed: 32834
[+] Getting new input..
securinets{vm_pr0t3ct10n_r0ck5!}
[+] Emulation done.
Убедимся, что мы действительно нашли новый путь:
./task
Welcome to SECURINETS CTF!
Give me the magic:securinets{vm_pr0t3ct10n_r0ck5!}
Good Job! You win!
Выводы
Благодаря тритону мы не потратили ни минуты на анализ обработчика байткода и сразу нашли все возможные решения. Можно пойти еще дальше и перевести символьные выражения в llvm байткод и пересобрать программу, полностью девиртуализируя вм, как это было сделано здесь. Кстати судя по тому, что нашелся лишь один новый инпут в программу, можно предположить, что алгоритм проверки ключа следующий:
bool check(char* input) {
if (strlen(input) != 32)
return false;
bool ret = true;
for (int i = 0; i < 32; i++)
if (input[i] /* магия над нашим вводом */ != /* какому-то значению */)
ret = false;
return ret;
}
Конец.